 links to sample pages or to previous vendor queries that illustrate a given feature.
links to sample pages or to previous vendor queries that illustrate a given feature.
Revision History
This symbol: links to sample pages or to previous vendor queries that illustrate a given feature.
The data-conversion vendor will return keyed and coded text files transcribed from the page images supplied by the corporate partner (UMI/ProQuest/Chadwyck-Healey in the case of EEBO; Readex/Newsbank in the case of Evans; Thomson/Gale in the case of ECCO).
Transcriptional accuracy will be 99.995% or better (error rate of 1 character/byte in 20,000). We will test and if necessary reject data by the book or (if several books need to be grouped together to provide an adequate sample), by the group of books or shipment. In assessing error rates we will use a set of published general principles to decide which errors could and could not reasonably have been avoided. Any policy changes on methods and principles of error assessment will be announced beforehand, with a definite start date, and will not be applied retroactively.
Coding will be valid SGML, validated against the supplied dtd or a true subset thereof. This dtd is an extract from TEI P3/P4 (with some slight modifications) and uses TEI semantics; the TEI guidelines (TEI P3 or P4) may be safely used as a general guide to the meaning of particular tags, though local usage may dictate some specific practices. TEI P3 documentation is available from Michigan online.
There is also a "cheat sheet" (prepared for purposes of internal training) that supplies a summary description of each of elements of the TCP tag set.
The vendor may, at its discretion, reject books submitted for conversion if they are deemed impossible to convert accurately. Valid reasons for rejection (which should be stated) include: (1) excessive abbreviation, and (2) illegible text (due to poor image or print quality).
Changes. We recognize the need for consistency, and the expense entailed in changing instructions and procedures midstream; such changes will certainly be minimized. Nevertheless, there is certain to be unexpected material in the data; and there are certain to be unforeseen consequences to some of the instructions given here. These instructions, as well as the eebo2sgm.dtd will therefore undoubtedly undergo some revision during the course of this project; most of it, probably, towards the beginning.
Exceptions. There is considerable variety in the source material and minor special instructions may rarely be required for some books, or some portions of books, in some cases overriding the instructions given below.
Specialized vs. general markup. As a rule, if it is not clear that something qualifies for specialized treatment, it can safely be captured as straight text. If you're not sure whether an elaborate treatment is justified, use the simpler treatment instead. This is almost always the safe thing to do: we don't lose any text that way, and we don't perpetrate any incorrect markup: better LESS markup than WRONG markup.
Feedback. Conversion firms involved in these projects are encouraged to ask questions: both to inquire about specific features not anticipated by the Guidelines, and to challenge the Guidelines (or the dtd) if they seem to produce unreasonable results. We will likewise provide advice on the conversion firms' tagging practices as quickly as possible.
The beginning of each page (including the first page and all blank pages) should be recorded with a <PB> tag. The REF attribute of the <PB> tag is required: its value should be the image number within the book. E.g., a page appearing on the the third page image will begin with <PB REF="3">; a page appearing on the seventh page-image will begin with <PB REF="7">. If it is necessary for some reason to capture the contents of the images in an altered sequence, the REF values must still reflect the original sequence, as reflected in the filenames of the tiff files.
Since most of the page images are in fact images of page openings (i.e., each image is "two-up": it contains an image of two facing pages), in most cases there will be two <PB> tags for each REF value, like this:
<PB N="6" REF="3">
<PB N="7" REF="3">
<PB N="8" REF="4">
<PB N="9" REF="4">
<PB N="10" REF="5">
<PB N="11" REF="5">
The text captured from each book should be returned as a single file, *.sgm (zipped up either singly or as a batch in a standard .zip file). Base the file name on the Wing or Pollard-&-Redgrave STC number (or, rarely, the Thomason Tract number if the other two are not available), prefixing "S" or "W" (or "T") to the name depending on whether the book is listed in the original Short title catalog of Pollard and Redgrave or its continuation by Wing, replacing any internal spaces, brackets, or periods with hyphens, and attaching an *.sgm extension. (This is *not* the same as the online "ESTC Record ID number.") The STC number is supplied in the <STC> element within the <IDG> element at the time the texts are assigned. Case is unimportant. Examples:
| For book with <STC T="S">12626A</STC> | use filename S12626a.sgm |
| For book with <STC T="W">B1210</STC> | use filename WB1210.sgm |
| For book with <STC T="W">T2021A</STC> | use filename WT2021A.sgm |
| For book with <STC T="S">10020.5</STC> | use filename S10020-5.sgm |
A resubmission of a file previously submitted should insert a "rev" (for "revised") in the filename, e.g. WB1187.rev.sgm.
The top-level <EEBO> element should contain as its first element a string of ID numbers that are associated with the book, contained in an <IDG> ("ID-group") element. These are numbers that we will use internally to track the document, attach headers to it, and link it to the appropriate set of page images. One of the ID numbers is the STC number, which also serves as the basis of the filename, as described above.
The entire ID string (enclosed in an "IDG" ("ID group") tag) will be supplied at the time of text assignment. You should be able to simply paste this string into the document, immediately after the opening of the top-level EEBO element.
Sample: <IDG S="marc" R="UM" ID="A01764">
<STC T="S">11900</STC>
<BIBNO T="umi">99838885</BIBNO>
<VID>3275</VID></IDG>
With a few standard exceptions noted below, the entire text will be recorded in its entirety, first page to last, in the order it was intended to be read (top left to bottom right, left column before right column, etc.).
The chief (and rare) exception is parallel texts. Running parallel texts, printed in a multi-column, multi-row, or facing-page arrangement, or some combination thereof, need to be treated as separate texts (normally, separate <DIV>s, sometimes perhaps separate <TEXT>s), each one recorded until
its end and not restarted on each page. Notes and other material relating to only one of the texts on a page needs to be
embedded in that text, not in any of the others. If a single heading or figure applies to more than one of the parallel texts, it should be recorded at the appropriate place in each text to which it applies.
Partial or fragmentary parallel texts will normally be broken primarily at the chapter or section level (e.g. <DIV1 TYPE="chapter">), then into parallel versions of that chapter (e.g. <DIV2 TYPE="version">) when necessary. But full parallel texts, e.g. an entire Latin-English parallel New Testament, or a Latin-English parallel Boethius) will normally be broken primarily into versions first (<DIV1 TYPE="version">), then each version into its chapters (<DIV2 TYPE="chapter">).
All material should be recorded in the form in which it appears in the book: do not attempt to correct spelling or typographic errors (except upside-down letters; see below). Spaces between words should always consist of one space character. Spacing between words is, however, often highly irregular in these books, often difficult to discern, and therefore often requires a measure of judgment. In cases of doubt, it may be necessary to use the sense of the passage to dictate its spacing. In other cases, when spacing is highly irregular, the preferable (but optional) treatment will involve occasionally and advisedly departing from the spacing that appears in the original book when sense demands it.
Page numbers as printed in the book will be preserved only as the value of the "N" attribute of the <PB> (page-break) tag. Unnumbered pages should receive a <PB> tag with the N attribute omitted. Incorrect page numbers, if they arise from typographic error, should be recorded just as they appear (otherwise: see comments on out-of-order pages). Page numbers will usually consist of arabic or roman numerals, but may also appear as letters or letter-number combinations. If there appear to be multiple separate paginations, choose one to record with the <PB> tag; record the other with a <MILESTONE> tag. Ignore any typographic elements used to set off the page number. E.g. -2-, {p. 2}, and PAGE 2 should all be recorded as <PB N="2">; (ccii) .cc.ii. and -ccii- should all be recorded as <PB N="ccii">; etc.
Placement of <PB> tags. The rules are: (1) "pages always break at the top"; that is, <PB> tags will be inserted in the text at the actual location of the page break (the "top" of the page), regardless of the location of the page number on the printed page. (2) "Divisions begin at page breaks; they don't end there"; that is, if a structural break of some kind coincides with the page break (e.g., if a new section (<DIV>), paragraph, stanza, etc., begins at the head of the new page, the <PB> tag should be tucked inside the opening tag for the first structural element, neither inside the closing tag for the old division nor between the two divisions. And (3) "Words cannot break at page breaks"; that is, if a hyphenated word straddles a page break, finish the word and any attached punctuation, then insert the <PB> tag. Treat the hyphen as any other end-of-line hyphen.
In parallel texts, material on a single page is often recorded at widely separated points in the data stream (once in each parallel <DIV>). In that case, the <PB> tag, including the page number, should be repeated, i.e., recorded in both <DIV>s.
Foliation. Some books may be foliated instead of paginated, i.e., every leaf may receive a number, rather than every page (in which case, typically, the back page of each leaf has no number). Record a foliated book in the same way as a paginated book, supplying the folio number as the value of the "N" attribute of the <PB> tag. A typical page sequence in this kind of book will look like this:
<PB N="iij"> <PB> <PB N="iv"> <PB> <PB N="v"> <PB>The folio number may be explicitly labeled as such ("Fol.xvii." or "Folio .cxli."). Discard the label and punctuation and record only the actual number (<PB N="xvii"> <PB N="cxli">).
Page breaks in unbreakable objects. Occasionally an object such as a table will spread across a two-page opening so that the opening becomes in effect a single page. (This is different from a table that is simply continued from one page to the next.) In this case there is no sensible place to insert the <PB> tag that marks the break between the left and right pages, so it should be inserted before the unbreakable object, with a double "N" value.
E.g., if a single table is spread across pp. 46 and 47 (both of them on image 22), the tagging should look like this:
<P> <PB REF="22" N="46-47"> <TABLE> ... </TABLE> </P>
Objects that span two or more IMAGES (as opposed to pages) are another matter.
These will usually need to be broken up into separate objects if it is not possible to insert
a <PB> tag within a single object. This happens fairly commonly with large
fold-outs, which may have been filmed in sections. In that case, each
piece of the original foldout must be tagged as a separate (e.g.) <TABLE>
with intervening <PB> tags to indicate the appropriate image on which the piece appears. (<FIGURE> will not normally need to be broken up this way, since <FIGURE> can contain <PB> easily.).
Other (largely) non-structural numerations and alternative numerations. If the book contains some other running numeration system alongside folio or page references, you may use the milestone element to record it. If the nature of the unit is obvious (e.g. chapter 1 -- chapter 2 -- [etc.]), you may use the "unit" attribute to capture that information: <MILESTONE UNIT="chapter" N="2"> <MILESTONE UNIT="chapter" N="1"> Note that this applies only to a sequence; occasional notes of this sort should be recorded simply as <NOTE>. If in doubt whether a set of numbers represents <MILESTONE>s or <NOTE>s, use <NOTE>. (Milestones can of course also be found embedded in notes that contain additional information). Some books contain conflicting structural enumerations, e.g. a system of proposition numbers in the margins that does not correspond with the chapter numbers; the former may be recorded using <MILESTONE> tags.
Some books mark the fine structure of the book or of the book's argument with marginal sequences of numbers. In many cases, such small units of structure (without headings) do not merit tagging as DIVs and the marginal indications can be readily tagged as MILESTONEs
<MILESTONE>s vs. <NOTE>s. A more elaborate description of <MILESTONE>s with examples is available in Coding Query #A2.
Line numbers in verse should be recorded only as the value of the "N" attribute of the <L> tag. Record in this fashion only line numbers actually printed in the book, and use the form of the number that appears in the book. (Line numbers in prose should usually be regarded as non-structural--that is, they do not correspond to any structure that we are tagging--and recorded as milestones, as above.)
Stanza, chapter, section numbers, etc. (that is, sequential numbers that appear in the headings to <LG>s and numbered <DIV>s) should be included as they appear in the book as part of the text surrounded by the appropriate <HEAD> tag, but should also be recorded, if possible as an arabic number, as the value of the "N" attribute of the appropriate <DIV> or <LG> tag.
<DIV2 TYPE="chapter" N="5"><HEAD>Chapter V.</HEAD><LG N="14"><HEAD>Stanza XIV.</HEAD>
Paragraph numbers (sequential numbers appearing at the beginning of a series of paragraphs that you have not chosen to regard as <DIV>s) should be included as they appear in the book as part of the text surrounded by the <P> tags, but should also be recorded, if possible as an arabic number, as the value of the "N" attribute of the <P> tag.
Item numbers and label numbers in lists should be recorded as part of the text included within the <ITEM> (or <LABEL>) tags. They should not be recorded as attribute values. See below under "Lists and Tables."
Enumerations in tables may be variously treated: given a column of their own, left as part of the text in a row, or even made part of an embedded <LIST>, whichever adequately represents the information most simply and efficiently. It is usually best to include the numbers as part of the text. See below under "Lists and Tables."
Language. Supply a value for the LANG attribute of numbered <DIV>s and of whole <TEXT>s, but do so only if the bulk of the text (barring notes) in that <DIV> or in that <TEXT> is in the indicated language. Supply the attribute at the highest level at which it applies: e.g., if an entire text is in Latin, add LANG="lat" to the <TEXT> tag, but not to all the <DIV> tags within that <TEXT>; if one of the <DIV1>s in a text is in Latin and other is in English, assign LANG="lat" to one of the <DIV1>s and LANG="eng" to the other; and so on.
Assign multiple LANG values to the same <DIV> or <TEXT> only if it contains two or more languages in some kind of organized relationship. E.g., a bilingual Latin/English dictionary should be coded as <TEXT LANG="lat eng"> (with a space between the two codes). Supply a value for the LANG attribute only if you are sure what language it is; otherwise, do not use the attribute at all. Use USMARC 3-letter language codes published by the Library of Congress at http://lcweb.loc.gov/marc/languages/ (These are identical to the 3-letter codes contained in the ISO standard 639-2; see http://lcweb.loc.gov/standards/iso639-2/langhome.html) Do not attempt to differentiate between forms of the same language: e.g., record LANG="fre" for French texts and LANG="eng" for English ones, not LANG="frm" ('Middle French') or LANG="enm" ('Middle English'). The proponderance of books and <DIV>s will in fact be in English (LANG="eng"), French (LANG="fre"), or Latin (LANG="lat"), but other languages may appear.
TYPEs of DIV. Supply a value for the TYPE attribute of numbered <DIV> elements if the appropriate value is obvious; otherwise, omit the attribute entirely. You may find it useful to consult our list of common and preferred DIV TYPEs. If you do supply a value, use these rules:
If the designation in the book is a verbose version of a common English term, use the simpler form. E.g., if the book says "Prefatory Remarks by the Author," you shouldn't be afraid to translate this into <DIV1 TYPE="preface">
Otherwise, use whatever is printed.
<DIV1 TYPE="poem">
<DIV1 TYPE="poem">
See further under Poetry, below.
MS. Any page that contains handwritten corrections, deletions, glosses, etc., should have the "MS" attribute of the <PB> tag for that page set to "Y". No other notice should be taken of handwritten material.
Provide attribute values only when instructed to and when there is specific information to supply. Do not supply values of this sort: TYPE="unknown" or TYPE="unspecified".
Captions. It is not always easy to distinguish between captions (which should be captured) and other text within the illustration (which should not be). Captions may appear below the illustration, above it, or even within it (e.g. on a "shield" or similar device), and may often be distinguished from other text by the fact that they provide a summary identification or description of the illustration. If in doubt, assuming that the text can be read, capture it.
Mixed text and illustration (e.g. where the woodcut frames the text, or where a block of text (e.g. a poem) is printed by means of woodcut, can in most cases be captured by treating the illustration per se and the text as separate items. In the case of a poem printed by means of woodcut at the bottom of a larger illustration, for example, it is often easiest to capture like this: <P><FIGURE></FIGURE></P><LG><L>... </L></LG>.
In-line illustrations, if they are truly in-line (that is, can be unambiguously located within a line of text) should be inserted (as <FIGURE>) within the text at the appropriate spot. If the appropriate location is not quite so obvious (e.g., an illustration occupying two or three lines of text inserted in the text or placed in the margin), use the rules for marginal notes (below). That is: if the correct location can be identified easily (e.g. by an identifying phrase, "as shown in this figure:") place the <FIGURE> tag within the text at that point; if not, simply place it after the nearest sentence-ending punctuation (e.g. a period or colon).
There is no firm rule as to *which* copy to keep and which to <GAP> out, except that it would be sensible to keep the better copy and exclude the worse one. Often it will be the second copy which is the better (it is because the photographers thought there might be something wrong with the first copy that they made a second copy). If there is a duplicate run of images, and one is complete and the other incomplete, normally you should keep the complete set and exclude the incomplete set. If the situation gets more complicated, e.g. if both sets are incomplete, but are missing different pages, or if only set is complete, but includes some bad images that can be replaced by images from the incomplete set, you may have to mix and match. In any case, the desired result is : the best possible text, from the best images, in the right order.
Any images that are given the <GAP> treatment should be represented by separate <GAP> tags for each page (not each image), rather than attempt to represent a span of pages or a span of images with a single <GAP> tag. This is so that each image, regardless of whether it is captured or not, will still be represented in the text by a <PB> tag. Each <PB> tag should, of course, point to the actual image number using the REF attribute.
Surrounding structures should be preserved if possible, at the highest level that applies. A line of verse quoted in Greek, for example, should be recorded as <Q><L><GAP DESC="foreign"></L></Q>; a paragrah in Greek as <P><GAP DESC="foreign"></P>; and a stanza in Greek as <LG><GAP DESC="foreign"></LG>.

Record as: the semicircle .18.5, <GAP DESC="foreign"> .21.7, <GAP DESC="foreign"> .23
Extended spans of music should be captured using a single <GAP> tag, so long as other material (such as text, illustrations, or a page-break) do not interrupt.
Lyrics printed between lines of music should be recorded as ordinary prose. At every point at which the line of lyrics ends and a line or two of musical notation appears, insert within the running prose a <GAP DESC="music"> tag.
Illegible text that cannot be read, for whatever reason, should be marked using variations on the "$" symbol:
| $ | = individual character or characters, less than a word. |
| $word$ | = a whole word |
| $span$ | = any span of two or more words, less than a page. |
| $page$ | = a whole page. |
| Additional variants are possible if it proves useful to flag some other piece of the structure as unreadable, e.g.: | |
| $para$ | = illegible paragraph |
| $line$ | = illegible line of verse or prose |
Unknown symbols or characters if they can be distinguished from illegible characters, should preferably be recorded as "#".
The illegibility threshhold. Two extremes should be avoided as far as possible: (1) using the illegibility markers promiscuously to avoid capturing text about which there is some difficulty; and (2) "creative" capture of text that really cannot be read, simply in order to avoid using the illegibility marker. We have prepared some examples of both overuse (EXAMPLE SET) and underuse (EXAMPLE SET 1; EXAMPLE SET 2; see also the bottom of SET 3) of the illegibility markers. It is admittedly not always easy to tell when a letter can be recognized with sufficient confidence to make its capture reliable.
One text or many? Most works will consist of a single <TEXT> containing a single <BODY> element (optionally also a <FRONT> and/or <BACK> element for front and back matter respectively). Some works will consist instead of a <GROUP> element that contains multiple <TEXT>s (each <TEXT> with its own <BODY> and, optionally, <FRONT> and <BACK>). The GROUP element will normally be reserved for items that contain several works published or bound together, each with its own title page, that were originally printed separately, e.g. the collected works of an author.
Embedded texts (i.e., documents of one sort or another embedded in a larger work), can often be successfully captured as quoted texts, using <Q><TEXT> ... </TEXT></Q>. See below under quotations.
The <BODY> (and, if necessary, the <FRONT> and <BACK> elements) will normally be divided into numbered <DIV>s corresponding to the main divisions of the text. Very simple documents, on the other hand, with no internal division (a work consisting of a single poem, for example, or tract containing only a series of paragraphs) do not require <DIV>s at all: <BODY><P> is sufficient. Use no more <DIV> layers than necessary.
The numbered <DIV> elements, from <DIV1> to <DIV7>, represent a hierarchy: the <BODY> (as also the <FRONT> and <BACK> matter) is subdivided into <DIV1>s; <DIV1>s, if necessary, are subdivided into <DIV2>s, and so on. <DIV>s divide into parts: with few exceptions, you need to have more than one of something to call it a <DIV>.
Individual small texts embedded within a larger work (e.g. entire poems quoted within a chapter of a treatise) should usually not be tagged as <DIV>s but should instead be placed within <Q> tags. The <Q> element may if necessary contain an entire <TEXT>, with its own <BODY>, <FRONT>, <BACK>, numbered <DIV>s etc. See further under quotations, below.
Useful clues to the DIV structure include:
In general, these are not sufficient to establish a <DIV> and should instead be recorded as ordinary text. Numbered paragraphs, for example, should simply retain the number as part of the paragraph (and as the value of the "N" attribute of the <P> tag), but there is no need to call the number a <HEAD> and therefore make the <P> a <DIV>.
<P N="3">¶ III. In the third place, the Calvinist partie striveth ...Marginal "headings" that you decide not to treat as <HEAD>s can usually be encoded either as <NOTE>s, with the PLACE attribute set to "marg" or (if they contain a sequential numeration), as <MILESTONE>s.
TYPES of DIVs. See above under "attributes."
Front matter (material to include in the <FRONT> element) typically includes title pages, dedications, tables of contents, prefaces, prologues, honorific poems, remarks "to the Reader", etc., each of which should be recorded with a numbered <DIV>, their subsections recorded with higher-numbered <DIV>s, etc., just as with <BODY>.
Title pages do not require special tags. Each title page should be recorded as a numbered <DIV> within the <FRONT> element. Include both the front and back (recto and verso), if there is material there to record. If there are multiple title pages, record each in a separate <DIV>. Most title pages can be recorded as simple blocks of prose text (recorded with <P>s). Other structural tags (e.g. <HEAD> or <EPIGRAPH>) should be avoided; verse quotations and illustrations on the title page should of course be recorded as such, using <LG>, <L>, <Q>, and <FIGURE>.
Back matter (material to include in the <BACK> element) typically includes indexes, glossaries, colophons, afterwords, appendices, etc., each of which should be recorded with a numbered <DIV>, their subsections recorded with higher-numbered <DIV>s, etc., as with <BODY> and <FRONT>.
Do not attempt to record the physical appearance of the page (centering, extra spaces, justification, type face, type size, etc.), though such cues may and should be used to determine the beginning and end of divisions within the text, the distinction between text and notes, etc. On type faces, see the special instructions below about use of the <HI> tag.
Record line-breaks (with the <LB> tag) only (1) if the text is unintelligible without a break; and (2) if the break is not reflected by a structural tag. Many times, it is better to repeat a tag than to insert a line break in the middle of one; but more often it is possible to get by without doing either, especially if there is any punctuation at the line break. E.g., record this:
CHAP. XI.
Some Advantages and Helps for raising
and affecting the Soul by Meditation.
like this:
<HEAD>CHAP. XI.</HEAD>
<HEAD>Some Advantages and Helps for raising and affecting
the Soul by Meditation.</HEAD>
or, better, like this:
<HEAD>CHAP. XI. Some Advantages and Helps for raising and
affecting the Soul by Meditation.</HEAD>
but NOT like this:
<HEAD>CHAP. XI.
<LB>Some Advantages and Helps for raising and
affecting the Soul by Meditation.</HEAD>
(However, some loosely formatted text can only be rendered intelligible by use of <LB> tags. See below for the special case of prose interrupted by an interlinear gloss.)
Paragraph breaks should be recorded with <p> in prose and with <lg> (line-group or stanza) in verse.
Do not record italic or bold type, the various kinds of black-letter ("gothic") typefaces, regular roman typefaces, or fonts of different sizes as such. Instead record every change from the predominant typeface with the <HI> tag, unless you use that change as a cue to insert a structural tag of some kind. For example, a book may have black-letter text and italic headings. Record the headings as <HEAD> ... </HEAD>, not as <HEAD><HI> ... </HI></HEAD>, since you have used the change to italic as a cue to tag the italic text as a <HEAD>
Predominance is established generally at the <DIV> level. E.g., if the Preface or Dedication or chapter or section (occupying its own <DIV>) is in italic, it needs no special tagging, even if the main body of the book is in some other typeface. But if an individual word, phrase, sentence, line, or paragraph is in some other face than that which is predominant in that <DIV>, then mark the "different" text with the <HI> tag.
The exception, of course, is again if you are using the change of type face as a cue to structural role: in a book that prints its text in roman and its notes or block quotations in italic, once you have recorded the italic text as a <NOTE> or a <Q>, you do not need to mark it also as <HI>. Instead, the italic type itself becomes the predominant form within the <NOTE> or within the <Q>; any changes of typeface within these tags (e.g. a single word in textura black-letter) should be recorded with <HI>
If the text switches to yet another typeface within a section flagged with <HI>, simply mark the new typeface with another (nested) <HI> tag.
If the text switches alternately to two different variant typefaces from one predominant one, record both "different" typefaces with <HI> (don't attempt to distinguish the two diffent kinds of <HI>).
The most common contrasting type forms may be described as: (1) roman; (2) italic; (3) textura; (4) rotunda; (5) bastarda (see letter samples below), but individual books may use other contrasting forms: subtypes of italic; changes of font size; etc. The general appearance of the book must be the key: if the book intends two kinds of type to contrast, then flag the change with <HI> (as instructed above).
EXCEPTION. Many books use a "diminuendo" effect both in headings and in the beginning of text divisions: for two or three lines of text, each line is smaller than the one above it, and is sometimes in a different typeface as well. This is simply decorative, and can usually be ignored; i.e., if this is clearly what is going on, do not code the lines of contrasting appearance with <HI>. You may instead need to determine what is the predominant typeface of each line and mark exceptions to that as <HI>.
Do not record changes of typeface within a word (e.g. a single letter or two in one typeface within a word that is otherwise in another typeface): either the whole word is <HI> or none of it is. The commonest examples of this consist of words that are in (say) italics except for the initial capital letter (probably because a capital letter in italics was not available); in this case, treat the entire word as if it were in italics. EXCEPTION: when a word is in italics (or is otherwise highlighted) except for a concluding "'s" (apostrophe-s), as commonly with names (Paul's), allow the <HI> tag to follow the print: <HI>Paul</HI>'s.
When punctuation coincides with the end of a span marked by the <HI> element, and there is doubt as to whether the punctuation belongs inside or outside the closing tag, place it within the closing </HI> tag:
<HI>Sillepsis,</HI> or the Double supply.
If two adjacent spans of text are in two different typefaces, both of which contrast with the predominant face as well as with each other, record the two spans with two separate sets of <HI>..</HI> tags.
Record superscripted and subscripted text using the keyboard "circumflex" or "caret" character (^ = DECIMAL 94, HEX 5E) before each superscripted character (^a;, ^b; 5^t^h; 2^n^d) and the same "caret" character doubled (^^) before each subscripted character (i.e., ^^a;, ^^b;, etc.).
Record large initials, "drop caps," etc., UNLESS THEY ARE DECORATED, as ordinary capital letters.
Decorated initials should be recorded using ordinary letters preceded by the underscore character (_). See our separate page of samples for help distinguishing decorated initials (which should not be specially marked) from decorated initials (which should).
Record "small caps" as ordinary capital letters.
Record vertical text (text printed perpendicularly to the main text) as if it were horizontal.
<Q>s are used for block quotations, whether of prose or verse. Don't use them for ordinary "inline quotations."
"Block quotations" include both quotations that are set off from the main text by indentation and blank lines (in the modern way) and also lengthy quotations that are set off by the use of other typographic cues such as (if unambiguously marking a block quotation) a change of typeface. If you're not sure if a block of text is a <Q>, simply record the appearance of the text (using, e.g. <P> and <HI>).
See below for the special problem of marginal quotations marks or marginal inverted commas.
<Q>s are usually the best way to tag even very substantial items embedded in prose, e.g. a poem or a document of some kind quoted within a chapter, or within a note, or within an introduction.
<Q> can if necessary even contain an entire <TEXT>, with its own <FRONT> matter, <BODY>, <DIV> structure, and so on. Use <Q> for such embedded items, rather than trying to treat them as <DIV>s of the main text (unless that's really what they are). Treating them as <DIV>s forces you to treat all the material surrounding them as <DIV>s too, at the same level.
Prefer this:
<DIV1 TYPE="introduction">
<P>blah blah</P>
<P>blah blah</P>
<P>
<Q>here's a poem</Q>
</P>
<P>blah blah</P>
</DIV1>
to this:
<DIV1 TYPE="introduction">
<DIV2 TYPE="stuff before the poem">
<P>blah blah</P>
<P>blah blah</P>
</DIV2>
<DIV2 TYPE="poem">
<LG><L>here's a poem</L></LG>
</DIV2>
<DIV2 TYPE="stuff after the poem">
<P>blah blah</P>
</DIV2>
</DIV1>
Block quotations accompanied by citations should record the quotation within <Q> tags and the citation within <BIBL> tags; the <BIBL> will normally be placed within the associated <Q>.
Most material that is set off from the main body of the text but is adjacent and related to it can be safely tagged as <NOTE>. (But arguments (summaries at the head of <DIV>s), salutations, and speaker names and stage directions in drama are among the note-like features that have their own tags.)
Record each note at the point in the main text to which it relates, set off by appropriate tags, not at the point where it appears on the page.
A note that spills onto the next page needs to be treated as a single note, not two, and should be placed in the text where it applies.
If the note points to a place in the text which is marked with a flag of some kind (e.g. a footnote reference number, an asterisk (*), etc.), discard this marker from both note and text once it has served its purpose by locating the <NOTE> in the right place in the text. The marker should be preserved only as the value of the "N" attribute of the <NOTE> tag. Notes that use non-alphabetical symbols such as "daggers," section-marks, paragraph marks, etc., should preserve those characters too in the "N" attribute if possible, using character entities, like this: <NOTE N="†">. If the character is not recognized as corresponding to a readily available character entity, supply "#" or "$" as the value, using the rules for unrecognized symbols.
Sometimes notes can be accurately placed only by noting their sequence. There may be three marginal notes on a page, for example, matched by three asterisks in the text; the first note is inserted at the first asterisk, the second note at the second asterisk, and the third note at the third asterisk.
If the note is keyed to the text by line number, verse number, etc., place the note at the end of the line (etc.) to which it applies, and discard the literal number from the note.
Use the "PLACE" attribute of the <NOTE> tag to indicate where the note appears on the page:
- PLACE="marg" in margin or adjacent to the text (even if part of it runs across the whole page because of lack of room in the margin, or if it is set into the edge of the text as a "shoulder" note)
- PLACE="foot" in a footnote, below the text
- PLACE="inter" interlinearly (between the lines of text)
If there are multiple distinguishable sets of notes in the same location (two sets of footnotes, for example; or multiple sets of marginal notes marked by different kinds of flags, one set marked by numbers, one by letters), distinguish them by appended numbers: PLACE="foot1" and PLACE="foot2" for example.

Example of book with two sets of marginal notes, one keyed to letters, one to numbers; record them as <NOTE PLACE="marg1"> and <NOTE PLACE="marg2">
Notes that apply to two (or more) distinct loci or lines should be reproduced and inserted at *both* (or all) the relevant points.
These need to be distinguished from notes that apply to a span of loci or lines; notes applying to a span of lines should be placed after the last line in the span with indications of the length of the span (e.g., "14-23" [with reference to line numbers] or "*-*" [with reference to two "*" flags in the text]) retained.
A note that appears next to a single verse line or set of lines and seems to relate to that line (or set) should be placed at the end of the line(s) in question.
Notes referenced to a line (verse, etc.) number followed by "f." ("2365 f." meaning "line 2365 and following") should be treated as notes referenced to a span of two lines (in this case, 2365-66), that is, placed at the end of the second line (2366), with the full line reference preserved in the note: <NOTE PLACE="foot">2365 f.: ... </NOTE>
A note that seems to relate to an entire text division (e.g. a <DIV> or <P>) should be inserted at the beginning of the text that comprises that division, or to end of the <HEAD> if that is more convenient (and if it has one). E.g. a marginal note applying to a paragraph as a whole may be inserted at the beginning of the paragraph. This occurs commonly in books that contain a running summary or set of running headers in the margins: if these are not treated as <HEAD>s, or <ARGUMENT>s, they should be treated as <NOTE>s (PLACE="marg") and inserted at the beginning of the section to which they apply. If the summary is found centered at the head of the text proper (instead of in the margin) it should usually be given a tag of its own and tagged as <ARGUMENT> or <HEAD> (see below under Heads").
A marginal note in a prose text that seems to apply vaguely to the material next to which it is placed should be inserted at the end of the nearest sentence (as marked by punctuation--a period, semicolon, or colon), or at some other break in the text if that seems more appropriate.
In the case of notes that supply bibliographic citations, similarity of wording between note and text may provide a clue as to the best place to insert the note, as in this example:
Democ.Instit. Antonius Demochares saith of him, that he was exiled Christ.relig. in the persecution under Diocletian, and that he returned from banishment after the death of Diocletian and Licinius, and recovered his Bishoprick again, where he continued until the reign of Iulian.
<P>Antonius Demochares saith of him,<NOTE PLACE="marg">Democ. Instit. Christ. relig.</NOTE> that he was exiled in the persecution under Diocletian, and that he returned from banishment after the death of Diocletian and Licinius, and recovered his Bishoprick again, where he continued until the reign of Iulian.</P>
A note that relates generally to the material on a page, or for which the appropriate place cannot readily be determined, should be attached to the last line of text at the bottom of the page.
Reference numbers in the text that point to something other than a note (e.g. to some part of an illustration), or for which the target cannot be found, should simply be recorded as part of the text.
Passages of verse (especially 2 or more lines, quoted and arranged as verse) within a note will normally be most readily coded as a quotation (<Q>) containing <L>s or <LG>s, embedded within the <NOTE> element.
Notes comprising a running interlinear commentary or interlinear gloss poses special problems. See below.
In general, prefer to record itemized sequences as <LIST>s rather than <TABLE>s if possible. Use <TABLE> when the material cannot be readily understood without the spatial organization that tables provide. It is sometimes possible to capture items outside the main text flow as <NOTE>s rather than resorting to a <TABLE>.
Numbered sequences of items when the items themselves are blocks of text of considerable size (numbered paragraphs, for example) should not be treated as lists, but simply as numbered paragraphs (<P N="3">3. ...).
Complex lists (lists within lists) should be encoded with nested <LIST> tags, i.e. a <LIST> tag within an <ITEM> of another <LIST>:
<LIST>
<ITEM> .. </ITEM>
<ITEM><LIST>
<ITEM> .. </ITEM>
<ITEM> .. </ITEM>
</LIST>
</ITEM>
</LIST>
Treat any numbers that enumerate items in a list as part of the text of that item; record them neither with separate <LABEL> tags nor as attribute values. E.g.:
<LIST>
<HEAD>Sins</HEAD>
<ITEM>1. Avarice</ITEM>
<ITEM>2. Sloth</ITEM>
<ITEM>3. Pride</ITEM>
</LIST>
Typical indexes and tables of contents can be readily tagged using simple lists containing only <ITEM>s, especially if there is punctuation between the items and the page numbers. Always prefer this option if possible. E.g.:
<LIST> <HEAD>M.</HEAD> <ITEM>Malva, Wild Mallow, 46.</ITEM> <ITEM>Maple, 87, 91.</ITEM> <ITEM>March Mallows, 59.</ITEM> <ITEM>Matricaria, Featherfew, 54.</ITEM> <ITEM>Meadow Saffron, 19.</ITEM> <ITEM>Medune celebrated, 35.</ITEM> <ITEM>Meleagris, checquer'd Daffedil, 52.</ITEM> <ITEM>Melilot, Plaister Claver, 46.</ITEM> <ITEM>Melissa, Balm, 59.</ITEM> </LIST>Even when punctuation is lacking (e.g. when the indexed item is left justified and the page number right justified, simple <ITEM>s will often do. Here is an example without punctuation (and including some nested lists):
<LIST> <HEAD>M.</HEAD> <ITEM>Man, <LIST> <ITEM>at variance with himself &c. 24</ITEM> <ITEM>An inbred malice in him 48</ITEM> <ITEM>Pindars account of him 97</ITEM> <ITEM>Vnable to judge of crimes 229</ITEM> <ITEM>He hath a will but not the power to resist God 125</ITEM> <ITEM>Prone to aggravate his own afflictions 254</ITEM> </LIST> </ITEM> <ITEM>Masanissa, his famous plot. 142 <ITEM>Mercy, <LIST> <ITEM>what it is 68</ITEM> <ITEM>How it differs from pitty Ib.</ITEM> </LIST> </ITEM> <ITEM>Michael Ducas, the great plague in his reign 267,268</ITEM> <ITEM>Mithridates, his cruelty 276</ITEM> </LIST>
OPTIONALLY, lists of pairs may be tagged with the element pair <LABEL> and <ITEM> (in that order). If you use this option, you may omit any "leader" (e.g. a dot leader) between the paired items. E.g.:
THE PLAYERS' NAMES
The Prince...............Jn. Longfellow
The Pauper...............Thomas Goodrich
Joan the Tappester........Jack Smithson
<LIST>
<HEAD>THE PLAYERS' NAMES</HEAD>
<LABEL>The Prince</LABEL><ITEM>Jn. Longfellow</ITEM>
<LABEL>The Pauper</LABEL><ITEM>Thomas Goodrich</ITEM>
<LABEL>Joan the Tappester</LABEL><ITEM>Jack Smithson</ITEM>
</LIST>
Tables should be recorded as you would using HTML tables, oriented by row, with the number of columns determined by the number of cells within the row. Use the spatial organization of the text to determine the number of rows and columns (not necessarily reflected in printed border lines). The ROWS and COLS attributes of the <CELL> tag should be used just like the ROWSPAN and COLSPAN attributes of the <TD> in HTML to indicate cells that extend across two or more rows or columns. Cells that contain a heading or label for a row (or column) should receive the attribute ROLE="label".
| EEBO dtd | HTML equivalent |
|---|---|
| <TABLE> | <TABLE> |
| <ROW> | <TR> |
| <CELL> | <TD> |
| <CELL ROLE="label"> | <TH> |
| <CELL ROWS=""> | <TD ROWSPAN=""> |
| <CELL COLS=""> | <TD COLSPAN=""> |
Particularly complex tables may be recorded (again as in HTML) with nested <TABLE> tags, i.e., a <TABLE> within a <CELL>, or by combinations of <LIST> and <TABLE>, i.e. a <LIST> within a table <CELL> or a <TABLE> within a list <ITEM>.
Physical arrangements that cannot easily be accommodated by our simple table model (e.g., labels with text running vertically) may need to be adapted and adjusted until they fit; it is more important to preserve the relationships between the items in the table than to preserve its exact layout.
Tables that continue from one page to the next may be tagged as one continuous table, with an embedded <PB> tag, especially if its headings are not repeated on the new page. If the headings are repeated, it is usually easier to close the old <TABLE> and open a new one on the new page.
These are to be distinguished from tables that spread across a page. See above under "Page breaks in unbreakable objects."
Complex tables containing only numbers or symbols (i.e., without any substantial textual content worth searching) should be captured as <FIGURE> as if they were illustrations. Note, however, that just as with the captions attached
to "real" <FIGURES>, the heading for the tables should
be included within a <HEAD>> tag inside the <FIGURE> tag.
For example, this table should be tagged like this: <FIGURE><HEAD>A Table of Houses for the Latitude of 51.degr.34. min. <HI>Sol in Aries.</HI></HEAD></FIGURE>

Here is a sample simple table (this one is simple enough that it could almost be done as a <LIST>). [For another example see ]

Recorded as:
<DIV TYPE="table">
<HEAD><HI>TABLE</HI></HEAD>
<HEAD>By this table, shall ye fynde the Epistles and Gospels, for the Son|daies, and other feastiuall dayes.</HEAD>
<P>FOR TO fynde them the sooner, shall ye seke for these capital letters, <HI>A, B, C D,</HI> whi|che stande by the syde of this boke alwaies, On or vnder the letter shall you fynde a crosse ✗, where the Epistle or the Gospell begynneth, and where the end is, there shal ye find an halfe crosse, $ And the fyrst lyne in this table is alway the e|pistle, and the seconde lyne is alway the Gospell.</P>
<TABLE>
<ROW><CELL ROLE="label" COLS="3">On the fyrst Sonday in Aduent.</CELL></ROW>
<ROW>
<CELL>Rom. xiii.</CELL>
<CELL>C</CELL>
<CELL>And for as muche as we knowe</CELL>
</ROW>
<ROW>
<CELL>Math. xxi.</CELL>
<CELL>A</CELL>
<CELL>Nowe when they drew nye vnto</CELL>
</ROW>
<ROW><CELL ROLE="label" COLS="3">On the second sonday in the Aduent.</CELL></ROW>
<CELL>Rom. xv.</CELL>
<CELL>A</CELL>
<CELL>what so euer thynges are writen</CELL>
</ROW>
<ROW>
<CELL>Luc. xx.</CELL>
<CELL>C</CELL>
<CELL>And there shall be signes</CELL>
</ROW>
</TABLE>
Headings at the head of text divisions and stanzas (<DIV>s and <LG>s) should be tagged as <HEAD>. Subheadings should be tagged with a second <HEAD> tag, with the TYPE attribute optionally set to "sub," i.e., <HEAD TYPE="sub">.
Some headings have special tags (see below). If heading-like material doesn't fall clearly into one of these special categories, use simple <HEAD>.
. "Idlenesse is lesse harmefull then vnprofitable occupation."
PUTTENHAM<EPIGRAPH> <Q>"Idlenesse is lesse harmefull then vnprofitable occupation."</Q> <BIBL>PUTTENHAM</BIBL></EPIGRAPH>
Epigraphs are a common place to find bits of non-roman script; record those bits with <GAP DESC="foreign"> as described above, but place the "foreign" portion inside the <EPIGRAPH> tag.
Commentaries and sermons frequently quote a passage of text at the beginning (or at the beginning of each division), then comment on it. Encode these passages as <EPIGRAPH><Q> ... </Q></EPIGRAPH>.
Material at the end of a text division that is set off from the main text is normally to be tagged as a <TRAILER> or <CLOSER>. <TRAILER> is the more general tag, used for material without such internal structures as datelines, salutations, or signatures. Typical <TRAILER>s include "Amen," "Finis," and title-like material such as explicits ("here ends the tract written by Master John Knox"; "Explicit liber de gubernatione Dei."). <CLOSER>, on the other hand, is the counterpart of <OPENER>; it is used when the concluding material includes lengthy or complex information, including datelines, salutations, or signatures, especially in letters. See Letters, below, for examples. Requests for prayer for the author's soul are typically recorded as <CLOSER>s.
Epigraphs and bylines can appear at the foot of a division as well as at its head (see above for a description of epigraphs).
<BYLINE> vs. <SIGNED>. It is not always easy to decide whether to use byline or signed for ascriptions of authorship. If the phrase actually uses "by" ("By Philip Sidney"), <BYLINE> is the better choice. If the item is a document that is normally signed in order to take effect (a letter, a will, an edict or proclamation), <SIGNED> is better.
Verse lines. Each verse line should be enclosed in <L> tags. Do not attempt to record the varying indentation of verse lines; pay attention to indentation only insofar as it indicates a stanza break or a "broken" line (see below).
Broken lines. Sometimes when a verse line is too long to fit on the page, its last word or two is placed (sometimes marked off with an opening bracket or opening parenthesis) at the end of the next line or at the end of the preceding line (wherever it fits best). Such detached bits of verse lines should be recorded if possible at the end of the line to which they really belong.
Mary had a little lamb, [snow. Its fleece was white as<L>Mary had a little lamb,</L>
<L>Its fleece was white as snow.</L>
Groups of lines (<LG>s).
<DIV1 TYPE="poem">
<L>When the cat's away</L>
<L>The mice will play</L>
</DIV1>
<P>A stitch in time saves nine.</P>
<LG>
<L>When the cat's away</L>
<L>The mice will play</L>
</LG>
<P>Too many cooks spoil the broth</P>
<P>John walked along, chanting constantly:
<Q>
<L>When the cat's away</L>
<L>The mice will play</L>
</Q>
But no one noticed.</P>
<P>John walked along, chanting constantly:
<Q>
<LG>
<L>Red rover Red rover,</L>
<L>Come over Come over</L>
</LG>
<LG>
<L>The bird's on the wing,</L>
<L>The dog's had his fling.</L>
</LG>
</Q>
But no one noticed.</P>
Lines vs. line-groups. It is often unclear when a group of lines has enough organization to be called a stanza (line- group <LG>). If in doubt, err on the side of fewer line-groups rather than more. And be consistent throughout a particular poem, so that a particular structure is not sometimes tagged as a <LG> and sometimes left untagged. Clues to look at include, in decreasing order of significance:
<LG>s vs. <DIV>s. It is not always easy to distinguish between <LG>s and <DIV>s: both can have headings; both can nest to create a structural hierarchy. Metrical units (true stanzas) are always <LG>s; verse paragraphs of irregular length are frequently best recorded as <LG>s, especially if they are not consistently supplied with headings. On the other hand, <DIV>s should be used for line-groups big enough to have true titles, or to appear in tables of contents. Any poem with its own title deserves its own <DIV>.
Groups of stanzas within a poem should receive a numbered <DIV> tag. In most cases, you will use only a single level of <LG> (no nesting), and treat it effectively as the lowest-level text division. Any grouping of stanzas is therefore recorded as a <DIV>.
Entire poems. Each poem will usually be recorded as a <DIV> of the appropriate number (<DIV1> etc.), with TYPE="poem". Don't try to distinguish between different kinds of poems, between poems and songs, etc. Any discrete item in verse is TYPE="poem". Poems may, of course be subdivided further into <DIV>s and <LG>s of various types. If a book consists of a single poem, then the <BODY> element constitutes the poem. If a poem is quoted within a prose context, it is usually easiest to treat it as a <Q>. See next.
Poetry mixed with prose. When poetry is truly interspersed with prose, and either the poetry is the predominant form, or there is no clearly predominant form, the prose should be recorded within <P> tags, the verse within <LG> tags. When poetry gives way to prose, close the <LG> and open a <P>; when prose gives way to poetry, close the <P> and open an <LG>, even if the actual prose paragraph, or even the last sentence, is not finished.
Exceptions:
Aside from a few special tags (below), prose drama should be recorded like other prose (in <P>s, etc.) and verse drama like other verse (in <LG>s, <L>s, etc.), including the rules for interspersed poetry and prose.
Cast lists. Cast lists (often headed "dramatis personae") should be recorded like other lists, with the <LIST> tag. Cast lists will commonly appear as separate <DIV>s (within the <FRONT> matter of a book if the book contains one play). For complex cast lists, use nested lists and labels to indicate cast groupings.
Stage directions. Stage directions should be recorded with the <STAGE> element. Stage directions sometimes appear between the columns of a multicolumn text, or in the margin, where they look like notes. In other books, they may be centered (as if they were headings) or indented (as if they were little paragraphs). They are occasionally typographically distinct (it italics; within parentheses; or both).
Speakers. The name (sometimes abbreviated) of the speaker is recorded with <SPEAKER>. In print, these appear at the head of a speech: e.g. typically above the first line of the speech (sometimes centered), in the margin, in an indented line of its own at the head of the speech, or in italics at the beginning of the first line of the speech. Regardless of where it appears in print, the <SPEAKER> tag is tucked into the beginning of the appropriate <SP> ("speech") tag.
Additional text associated with the speaker's name may be included in the <SPEAKER> tag, if that is the most convenient way to do it, like this: <SPEAKER>Mr. Jones, reading from letter.</SPEAKER> Multiple names should be enclosed in a single set of <SPEAKER> tags, like this: <SPEAKER>Mr. Jones and Mrs. Smith.</SPEAKER>
Speeches. The basic unit of drama is the SPEECH (<SP>). A speech normally continues uninterrupted as long as the character speaking it is uninterrupted by another speaker or by the end of a division (act, scene, etc.). If a speech begins or ends in the middle of a verse line, break the line: i.e., treat it as two lines, one in one <SP> and one in the next.
"Songs" and other material specially set off within a speech should not normally be given any special tagging; if they have headings, they may need to be recorded as a nested <LG>. In exceptional cases when they contain an elaborate structure they may be recorded as a quotation (<Q>).
Prologues and Epilogues should normally be treated as part of the play, recorded as <SP>s like any other speech, though they may sometimes require a numbered <DIV> of their own.
Acts and Scenes. The act/scene structure should be recorded with appropriately TYPEd and numbered <DIV>s (e.g., <DIV2 TYPE="act" N="3"><HEAD>ACT III</HEAD><DIV3 TYPE="scene" N="4"><HEAD>Scene iv</HEAD><SP>...).
Personal letters that appear as text divisions should be treated as <DIV>s just like any other text division (chapters, sections, etc.). Letters quoted within running text (e.g. a letter quoted within the chapter of a book) have been given a special tag, <LETTER>. The <LETTER> element is simply a shortcut for <Q><TEXT><BODY><DIV1 TYPE="letter">.
Note that dedications frequently look like letters, since they contain salutations and signatures, but they're not: treat them as <DIV TYPE="dedication">. (You may, however, still use <OPENER> <CLOSER&> <SIGNED> <SALUTE> etc. in such letter-like divisions, if they apply.)
Special tags are available to tag the salutations (<SALUTE>), signatures (<SIGNED>), and datelines (<DATELINE>) often found in letters. Use these only if they clearly apply.
Place <SALUTE>, <SIGNED>, and <DATELINE> within <OPENER> if they appear at the head of a letter; place them within <CLOSER> if they appear at the end. See the TEI guidelines for fuller descriptions of these elements. If salutations and signatures are combined or confused in a single opener or closer, use the <OPENER> or <CLOSER> tag alone, without trying to tag the separate constituent parts.
. Slightly more complex ones may be able to be recorded with <P>s (one <P> for each entry). But more elaborate dictionaries will require numbered <DIV> elements to represent dictionary entries. The headword for each entry (with any associated grammatical information) can usually be recorded as a <HEAD> to the <DIV>. Complex entries can be subdivided if necessary into component parts using higher-numbered <DIV>s. For example, the following entries from Cotgrave's French-English Dictionary of 1611 ...
Affaicter. To trim, tricke, decke, dresse curiously, make neat, spruce, fine; to refine; also, to tame, reclaime, breake, make gentle, bring to ciuilitie.
Affaicter vn oiseau. To man a hauke throughly.
Affaicterie: f. A trimming, tricking, decking, neat, quaint, or fine dressing; also, neatnesse, nicenesse, curiositie, quaintnesse; also, a breaking, taming, reclayming, ciuilizing, making gentle; (hence) also, the through manning of a hauke, &c.
...can be recorded like this. The encoding of the phrasal subentry for "Affaicter vn oiseau" with a <DIV2> is probably superfluous in this case (a new paragraph with a <HI> heading would do as well); it is encoded more thoroughly here as an example of what can be done with more complexe entries if necessary.
<DIV1 TYPE="entry"><HEAD>Affaicter.</HEAD>
<DIV2>
<P>To trim, tricke, decke, dresse curiously, make neat, spruce,
fine; to refine; also, to tame, reclaime, breake, make gentle, bring
to ciuilitie.</P>
</DIV2>
<DIV2 TYPE="subentry">
<HEAD>Affaicter vn oiseau.</HEAD>
<P>To man a hauke throughly.</P>
</DIV2></DIV1>
<DIV1 TYPE="entry">
<HEAD>Affaicterie: f.</HEAD>
<P>A trimming, tricking, decking, neat, quaint, or fine dressing;
also, neatnesse, nicenesse, curiositie, quaintnesse; also, a breaking,
taming, reclayming, ciuilizing, making gentle; (hence) also, the through
manning of a hauke, &c.</P></DIV1>

Word-for-word interlinear gloss in (?) verse:
<L>Dirae
<NOTE PLACE="inter">fendes of fu|ryes of hell</NOTE>
& opes
<NOTE PLACE="inter">ryches</NOTE>
Charites
<NOTE PLACE="inter">thre goddes of fauour</NOTE>
cheae&abque;
<NOTE PLACE="inter">brachia scor|pionis</NOTE>
facetiae
<NOTE PLACE="inter">vrbanitates</NOTE>
[...] </L>
<L>At&abque; fores
<NOTE PLACE="inter">a payre of gates</NOTE>
furiae
<NOTE PLACE="inter">fendes of hell</NOTE>
Parcae
<NOTE PLACE="inter">thre goddes fatall</NOTE>
Gratiae<NOTE PLACE="inter">thre goddes of fauour</NOTE>
quo&abque; [...] </L>
In general punctuation should be retained, but its spacing somewhat regularized. When a colon, semicolon, comma, question mark, closing quotation mark, or period falls between words, place a space after it, but none before it (unless it is being used to set off a number, like this: .lxvi. or .45. in which case it should be spaced as shown; that is, the periods should "hug" the number on front and back, without spaces.). When an opening quotation mark falls between words, place a space before it, but none after it. When a virgule falls between words, place a space before and after it. In case of doubt, follow the spacing of the original as best you can.
Record the various forms of colon, period, comma, semicolon, and virgule (slanted line) with their modern keyboard equivalents ( : . , / ); a vertical bar should be recorded using the | entity (since we have reserved the keyboard character for another purpose).
Question marks vary considerably in form (some of them looking like inverted semicolons); record them all with the standard "?"
Opening and closing double quotation marks should both be recorded using the ordinary keyboard double-quote character (" = HEX 22), not the “ and ” entities.
Opening and closing single quotation marks, as well as apostrophes, should be recorded with the same character, the ordinary keyboard single-quote character (' = HEX 27)
Hyphens (not dashes) should normally be recorded using the ordinary hyphen character.
Hyphens at the end of a line should be recorded as the ordinary keyboard "pipe" (vertical bar) character, unless they appear between numerals, when they should be recorded with the ordinary hyphen. Be aware that hyphens in many texts may appear as an angled stroke, not a horizontal one, and may also commonly appear doubled, resembling an equals sign (=), either horizontally or at an angle, like this: 
If there is no end-of-line hyphen, but you think that there should have been (i.e., that a single word has been broken across two lines), place a plus sign, instead of a space, between the two halves: "cro+wn" "pri+nce". We recognize that since this requires interpretation of the text, it must remain an optional instruction subject to the discretion of the vendor.
Dashes should be recorded using the entity —, regardless of where they appear, or how long they are.
The "minus" sign (−), if it can be distinguished from the m-dash, should be recorded with a character entity (−).
The "times" (multiplication) sign (×), if it can be distinguished from the "X", should be recorded with a character entity (×).
Ellipses, whether two characters or many--strings of dots or asterisks indicating omitted or missing text--should be recorded as ordinary text, not the … entity, using periods or asterisks as appropriate: . . . . . * * * * * . .
Some books mark extended quotations by placing quotation marks at the beginning of every quoted line. The same technique is used in other books to mark proverbs and other sententious remarks. E.g.,
he made reasons...seyenge: God made alle thynges
" by reason, and governethe thynges
" made by reason; the sterres be movede by reason; and so
" oure naturalle lyfe excedynge from reason by slawthe and
" ignoraunce awe to be reducede by lawes and reasons.
" Wherefore thau3he there be somme thynges in the rule of
" seynte Benedicte, the intellect of whom the dullenesse of my
" mynde may not comprehende, y suppose hit be beste to 3iffe
" credence to auctorite. Wherefore also he persuadeth hymselfe ...
O no (said Cecropia) company confirmes reso-
" lutions, & lonelines breeds a werines of ones thoughts,
" and so a sooner consenting to reasonable profers.
In prose, record the first and last of the marginal quotation marks with the special entities &startq; (first mark) and &endq; (last mark). If there is only one such marginal quotation mark (as sometimes happens with short quotations or proverbs), use both entities in sequence (&startq;&endq;).
In verse, simply record the quotation marks using the " character as it appears in the print.
Braces and brackets that group multiple lines should be ignored if all they do is group portions of ordinary running text, such as poetry. But if they are used to link one piece of text to another, such as frequently in tables and lists, their meaning needs to be interpreted. Sometimes this will require entering text more than once, e.g. if the brace means "this word applies to all these other words," the easiest technique may be simply to apply the word to all of the other words by entering it as many times; sometimes it may require treating the single item as a head or label for a list containing the grouped items; sometimes it may involve attaching a ROWS or COLS attribute to a table <CELL>. Many variations are possible, which the following examples can only suggest.
| chapter |  | 1 How to build a kite | |||||
| 2 When to fly a kite | |||||||
| 3 Famous kite flyers of our time | |||||||
| 4 When not to fly a kite | |||||||
| 5 "I've flown it: now what?" | |||||||
| (Brace used like "ditto" mark to associate one word repeatedly with a series of items; may be recorded as follows, by repeating the word:) | |||||||
<LIST> <LABEL>chapter 1</LABEL> <ITEM>How to build a kite</ITEM> <LABEL>chapter 2</LABEL> <ITEM>When to fly a kite</ITEM> <LABEL>chapter 3</LABEL> <ITEM>Famous kite flyers of our time</ITEM> <LABEL>chapter 4</LABEL> <ITEM>When not to fly a kite</ITEM> <LABEL>chapter 5</LABEL> <ITEM>"I've flown it: now what?"</ITEM> </LIST> | |||||||
| Dramatis Personae | |||||||
|---|---|---|---|---|---|---|---|
| townspeople |  | Joe | |||||
| Mary | |||||||
| Bothom | |||||||
| Josephus | |||||||
| Joan, a noblewoman | |||||||
| John, a philosopher | |||||||
| (Brace used to associate one item as a head of a set of other items; may be recorded as follows, placing the one item in <HEAD< tag and the list of items in <LIST> and <ITEM> tags:) | |||||||
<LIST> <HEAD>Dramatis Personae</HEAD> <LABEL>townspeople</LABEL> <ITEM> <LIST> <ITEM>Joe</ITEM> <ITEM>Mary</ITEM> <ITEM>Bothom</ITEM> <ITEM>Josephus</ITEM> </LIST> </ITEM> <ITEM>Joan, a COuntess</ITEM> <ITEM>John, a philosopher</ITEM> </LIST> | |||||||
| |||||||
| (Brace used in a table to place one cell in conjunction with a set of other cells; may be recorded using the COLS or ROWS attribute of the <CELL> tag:) | |||||||
<TABLE> <ROW> <CELL>In apice trianguli.</CELL> <CELL ROWS="3">Triangulus.</CELL> </ROW> <ROW> <CELL>In basi praecedens 3.</CELL> </ROW> <ROW> <CELL>Sequens & vltima. 3.</CELL> </ROW> </TABLE> | |||||||
Basic letter forms. Most letters encountered will belong to the modern alphabet, though their appearance may be strange.
Ligatures. Ligatured characters (ae, oe, ct, st, sp, fi, ff, ss, etc.) should be recorded as two separate characters. Ignore the ligature. Initial AE and OE ligatures, when the rest of the word is in lower-case, can safely be captured as "Ae" (or "Oe") rather than "AE" (or "OE"), e.g.: "Aesop" "Oengus". Be aware that italic fonts especially tend to have ligatures between many more pairs of letters than we are accustomed to seeing. Be aware also that the italic "ae" ligature usually has no upper bow to the "a" and is easily mistaken for "oe".
| This is an "oe": |  |
| These are all "ae": |    |
The common form of the "ss" ligature that consists of a tall-s followed by a short-s has sometimes caused problems in recognition. Here are two examples:
 |
= possibility |
 |
= Passion |
Fractions. For the fifteen common fractions listed in either ISOpub or ISOnum (namely:
½,
¼,
¾,
⅛,
⅜,
⅝,
⅞,
⅓,
⅔,
⅕,
⅖,
⅗,
⅘,
⅙,
⅚,
)
, use the entity. Otherwise, simply use the "front slash" (virgule) character between the
numbers (e.g., 23/47).
NOTE: Some documents use dual dates (e.g. "12/22 Dec. 1635") because of the discrepancy of ten days between the calendars of different countries caused by the adoption of the Gregorian calendar. These are not really fractions at all, though they look like fractions; they should always be recorded using the "slash" method: 12/22. Likewise dual-year dates (e.g. 1651/2 or 1667/68) are frequently printed so that the end of the date looks like a fraction. Again, it is not; these should always be captured using the slash (1651/2; 1667/68).
Ampersands, whether shaped like & or like "7," should be recorded as &.
Some examples of ampersands (&)
"Old-style" roman numerals. Of the letters used commonly in Roman numerals (I V X L C D M), two,
namely "M" and "D," can appear in a variant form that makes
use of an extra character that resembles a backwards-facing
letter "c," combined with "I" and regular "c". E.g., this means "M.D.C.": 
(Since
I can't represent a backwards "c" on the keyboard, I'll
use "(" for "c" and ")" for backwards-c in what follows.) "(I)" is a variant form of "M"; "I)" is a variant form of "D" (If you look closely, you'll see that "(|)" almost looks like
an "M" and "I)" almost looks like a "D"). When you find this style of Roman numerals, represent the combination "(I)" as "M" and "I)" as "D". For further examples, see the document on roman numerals.
Letters printed upside-down (a common printer's error), or 'slipped' letters (pieces of type accidentally displaced in the printing form), if recognized, should be recorded as if turned right side up or restored to their proper place. There are some examples of upside-down type here; and an example of displaced type here:
 |
| Capture the initial words of these lines as:
To leaue... Some one ... If she ... And therefore ... If short... Both short ... |
The "plus" sign (+) should be recorded with a character entity (+), since we have reserved the keyboard "+" sign for special use.
The "less than" sign (<) should be recorded with a character entity (<), since we have reserved the keyboard "<" sign to mark SGML tags.
The "greater than" sign (>) should be recorded with a character entity (>), since we have reserved the keyboard ">" sign to mark SGML tags.
The "dollar" sign ($) if it ever appears in the text should be recorded with a character entity ($), since we have reserved the keyboard "$" sign for special use.
Recognizable letters with diacritics
| Some examples of 'macrons' (~) | |||||
|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
 ) in some typefaces (especially in the Bastarda group). These should not, of course, receive any treatment other than as an ordinary letter. See also the special document on Roman numerals.
) in some typefaces (especially in the Bastarda group). These should not, of course, receive any treatment other than as an ordinary letter. See also the special document on Roman numerals.| Some "general" abbreviation diacritics | |||
|---|---|---|---|
 | <ABBR>Cantuar</ABBR>, |  | <ABBR>clico</ABBR>, |
 | <ABBR>Cantuar</ABBR>, |  | <ABBR>clico</ABBR>, |
 | <ABBR>Suff</ABBR>, |  | <ABBR>qd</ABBR>, |
 | <ABBR>Marchionis</ABBR> |  | <ABBR>Ric</ABBR> |
 | <ABBR>Alred</ABBR> |  | <ABBR>vl</ABBR> |
 | <ABBR>red</ABBR> |  | <ABBR>apd</ABBR> |
| Some common abbreviations by superscript | |
|---|---|
| "thou" (y^u) |   |
| "that" (y^t) |      |
| "the" (y^e) |   |
| "with" (w^t) |  |
| Symbol | Record as: | Meaning | Examples: | conditions: |
|---|---|---|---|---|
 | &abper; | per, par |    | |
 | &abpro; | pro |   | |
 | &abus; | -us | 


| at the end of a word only |
 | &abque; | -que |     


 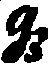
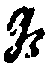
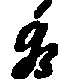

| at the end of a word only |
 | &abquod; | quod/quoth |







| |
 | &absed; | sed |  | only when forming a word by itself |
 | &abser; | ser | .. | |
 | &abcon; | con- cum- |   | at the beginning of a word only |
 | &abrum; | -rum |  | at the end of a word only |
 | &abis; | -is |       | at the end of a word only |
 (p);
(p);  (q);
(q);  (d).
(d).Letters from other alphabets, e.g. Hebrew and Greek, when used singly (as opposed to in whole words or extended text) should be recorded with ISO standard character entities.
Other symbols include alchemical and astrological symbols, which will rarely if ever appear as part of words, but may appear in or as marginal notes, in designations of units of measure, in calendrical tables, etc.
| Symbol | Example | Meaning | Record as |
|---|---|---|---|
| Zodiacal signs | |||
 |  | Aries | &Aries; |
 |  | Taurus | &Taurus; |
 |  | Gemini | &Gemini; |
 | Cancer | &Cancer; | |
 | Leo | &Leo; | |
 | Virgo (may also appear as abbreviation for "minim" ('drop') in medical recipes) | &Virgo; | |
 | Libra | &Libra; | |
 | Scorpio (may also appear as abbreviation for "minim" ('drop') in medical recipes) | &Scorp; | |
 |  | Sagittarius | &Sagitt; |
 |  | Capricorn | &Capri; |
 |  | Aquarius | &Aquar; |
 |  | Pisces | &Pisces; |
| Planetary signs (used in alchemy also for corresponding metals) | |||
 |  | Sun (or gold) | &Sun; |
  |   | Moon (or silver) | &Moon; |
 |   | Mercury (the planet or the metal) | &Merc; |
 |  | Venus (or copper) | &Venus; |
 | Earth (the planet) | &Earth; | |
 |   | Mars (or iron) | &Mars; |
 |  | Jupiter (or tin) | &Jupit; |
 |   | Saturn (or lead) | &Saturn; |
| Other astrological signs | |||
 |
 |
Conjunction = 0° (astrology/astron.) | &conjunction; |
 |
 |
Opposition = 180° (astrology/astron.) | &opposition; |
 |
 |
Trine = 120° (astrology/astron. context only; cp. Greek delta, etc.) | &trine; |
| Apothecaries' symbols | |||
 |
   |
ounce (apothecaries' unit of measure) | &ounce; |
 |
   |
dram or drachm (apothecaries' unit of measure) | &dram; |
 |
  |
scruple (apothecaries' unit of measure) | &scruple; |
 |
"Recipe" ('take ...') in recipes and prescriptions | ℞ (from ISOpub) | |
 |
    |
"Semis" ('half') with units of measure | ss (not really a symbol, just the ordinary letter "s" doubled; the second, variant form is rare and should perhaps be marked by <ABBR> tags around the basic "ss" capture.) |
| Alchemical signs | |||
 |
 |
antimony | &antimony; |
 |
 |
sal armoniac (in (al)chemical contexts only) | &salarmon; |
 |
 |
fire (in (al)chemical contexts only) | &fire; |
 |
 |
water | &water; |
 |
earth (the element) | &earth; | |
 |
 |
subli- (forming words like "sublimate") | &absubli; |
 |
 |
precip- (forming words like "precipitate") | &abprecipi; |
 |
  |
sulphur or sulphu- (forming words like 'sulphuris') | &sulphur; |
 |
 |
oil or oleum | &oil; |
 |
 |
tartar (tartrate? tartaric acid?) | &tartar; |
 |
 |
vitriol (sulphuric acid) or vitrio- (forming words like 'vitriolata') | &vitriol; |
 |
 |
salt | &salt; |
 |
 |
nitre or saltpetre (potassium nitrate) | &nitre; |
| Other signs | |||
 |    | cross (any variety: Greek, Latin, Maltese) | ✗ |
 |   | capitulum (paragraph) | ¶ |
 | right-pointing index finger (left-pointing finger also found) | &rindx; &lindx; | |
Symbols and marks not listed here
Dubious characters.Individual characters that cannot be readily identified as one thing or another ("is this a funny-looking "q" or some kind of symbol?" "Is this a "c" or a "t"?) should be recorded as "$". -->However, do not overuse this expedient: if the same symbol recurs repeatedly in a book, please ask us for help in identifying it; do not simply record dozens or hundreds of examples of the same symbol with "$" or "#".
"Excessive" abbreviation. If sampling shows that more than one word in every ten in a given text contains an abbreviation symbol, a dubious mark or peculiar symbol ($), or an <ABBR> tag, the work should be rejected for conversion.
The following samples are far from a definitive list of letter forms, but are meant only to provide some help recognizing the most common letters in the most common typefaces. Many books will have to be considered individually, the form(s) of each letter ascertained by its presence in a recognized word or unambiguous context so as to create, in effect, an alphabet or set of alphabets for that book. The samples below are arranged under headings that describe the most common families of type: roman, italic, textura, rotunda, and bastarda. There are many variants of each of these (except rotunda, which is fairly uniform) which may differ very considerably from the examples given here. And individual misprinted and ill-aligned letters may present a very anomalous appearance.
| Record as: | Textura | Italic | Bastarda | Rotunda |
|---|---|---|---|---|
| a |  |  |  |  |
| b |  |  |   |  |
| c |  |  |  |  |
| d |   |  |   |  |
| e |  |  |  |  |
| f |  |  |  |  |
| g |  |   |  |  |
| h |   |   |  |   |
| i |  |  |  |  |
| j |  | |||
| k |   |  |  | |
| l |   |   |   |  |
| m |   |  |  |  |
| n |  |  |   |  |
| o |  |  |  |  |
| p |  |  |  |  |
| q |  |  | ||
| r |    |  |    |   |
| s |   |   |    |   |
| t |  |  |  |  |
| u |  |  |  |  |
| v |   |   |  |  |
| w |  |   |   |  |
| x |  |  |  | |
| y |   |  |  |  |
| z |  |  |







